文档分析机器人自营店语音识别开发套件人脸抓拍门禁考勤机
百度AI市场





AI语音评测
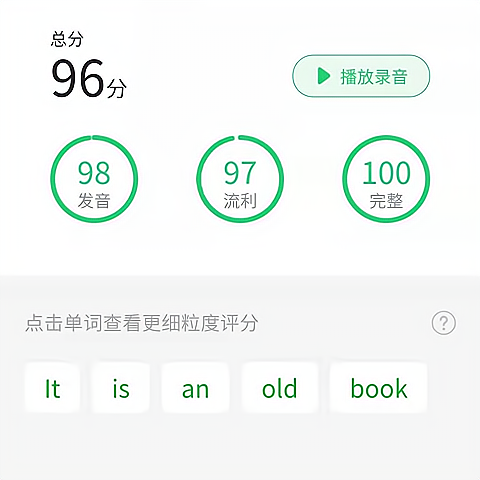
基于专家评分标准而研发的发音打分技术,年龄覆盖儿童到成人,支持音素(音标)、音节、单词、句子、段落、连读、重音、爆破音、等全维度的打分机制。
含税价格:
¥10 /1000次
商品规格:
购买类型:
库存不限
交付说明:
人工交付、应用软件交付
7天内交付
开票信息:
支持开具增值税专用发票(可抵扣)、增值税普通发票(不可抵扣)
服务保障:
质保期1年
产品详情
产品亮点
1、多语言支持,英语,汉语,日语,法语;
2、各年龄段动态自适应,为不同用户提供最专业的评测服务;
3、支持音素(音标)、音节、单词、句子、段落、开放题、封闭题、等中高考考试题型评测及识别;
4、多维度,支持音质、准确度、完整度、韵律度、流利度、重读、连读、爆破、音节、音素、逻辑准确度等,提供全方面评测;
5、支持大规模、大数据量、高并发;
6、支持评分松紧度自由调节,适应多种评分标准。
产品说明
1、声通语音评测技术介绍:

我们基于 GAN 研发了数据增强算法,使得我们的训练数据可以覆盖各种噪音场景,从而训练得到的声学模型针对各种环境下的音频都有较好的适应性。
2)声学模型
我们采用 LSTM 声学模型,可以让神经元“记住”已经处理过的数据,采用该模型建立的声学模型准确度上优势明显,并且我们自主研发了计算加速引擎,相比其他使用传统 RNN 或者 CNN 模型的技术更具有市场竞争力。 在开放式口语题目的评分中,我们将 end2end 和 TDNN-HMM-hybrid 相结合, 前者可以提升语音识别准确率,尤其是带有口音的中国学生的英语口语,后者可以针对每一个音素 (phoneme), 包括音素的上下文环境精准建模;两者形成优势互补,显著地提升了评测效果。
3)评分模型
声通聘请了多位资深英语专家凭借多年行业经验,按评价标准模型在大量真实用户的语音上给出了各个维度的评价分值,然后使用多种不同的回归方法(ensemble)建模从而得到更加精准的评分模型,评分标准也得到了绝大部分客户的认可。
4)针对年龄段自适应
声通专有的声学模型集(STSpectrum)能自动检测用户所处的年龄段,并且根据年龄段匹配最佳的声学模型从而达到最佳评分效果。。
2、评分维度
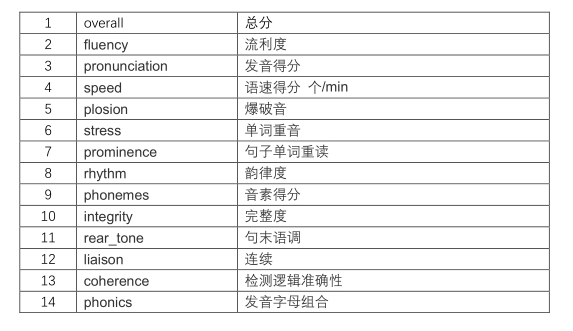
3、支持题型
1)语音评测:音标评分、字母评分、单词评分、句子评分、段落评分、有限分支识别、自由识别、音频比对
2)考试题型:短文朗读、短文跟读、句子翻译、段落翻译、故事复述、看图说话、情景对话、口头作文
应用场景
1、口语考试,中高考英语口语考试逐步普及,口语考试能力愈发重要。声通支持各地中高考口语题型,应用于英语正式口语考试,模拟考试等系列考试场景下的语音评测。
2、教学应用,英语口语考试实施,推动教学方式的更迭。通过智能语音评测技术,为老师提供全方面的口语教学工具,提升英语口语教学能力,帮助教师掌握个体学习情况。
3、日常练习,日常口语教学,作业,测验都需要大量的课后练习,通过语音测评产品,为学生提供课前预习,课后的练习等常用学习功能。
价格说明
| 商品规格 | 交付清单 | 数量/时长 | 含税价格 |
|---|---|---|---|
| 默认 | SDK交付 1次 | 1000次 | ¥10 |
售后服务
发票信息
支持开具增值税专用发票(可抵扣)、增值税普通发票(不可抵扣)
服务保障
质保期: 1年